
로켓펀치의 전문기술 정보
로켓펀치에는 다양한 종류의 비즈니스 정보들이 있습니다. 홈페이지를 보면 상단 네비게이션 바의 네트워크, 기업, 채용, 투자, 비즈니스 맵 등이 상위 항목 정보로서 여러 가지 또다른 세부 정보를 가지고 있는 것을 알 수 있습니다. 이 중에서도 사람과 기업, 채용정보는 전문기술 정보를 포함하고 있는데 이는 이용자가 각 항목에서 알고 싶은 내용들을 나타내고 있습니다. 우리가 어떤 사람이나 기업에 대해서 ‘이 분은 어떤 걸 잘 하는 걸까?’, ‘여기서 사용하는 기술들은 뭐지?’와 같은 궁금증을 가지는 것은 자연스러운 일입니다. 구인을 하는 기업 입장에서 어떤 기술을 가진 사람을 원하는지 나타내는 것도, 구직을 하는 입장에서 기업이 어떤 스킬을 가진 인재를 원하는지 알아야 하는 것도 당연합니다.
전문기술의 특징
전문기술은 다른 정보와는 조금 다른 특징을 가지고 있습니다. 개인의 경력이나 기업의 이력과 같은 정보들은 각 항목이 변하지 않는 사실을 담고 있으며 여러 가지 항목의 중요도 또한 큰 차이가 없습니다(정말 알리고 싶지 않은 사실이 있다면 이야기가 다르겠지만요). 반면에 이 전문기술이라는 정보는 그 시점과 환경에 따라 각 항목의 중요도가 달라집니다.
어떤 개발자가 자신의 전문기술 항목을 채워넣을 때를 생각해보겠습니다. 이 사람은 아마도 현재 자기가 주로 다루는 프로그래밍 언어를 입력할 겁니다. 그리고 여러 가지 라이브러리와 주로 사용하는 도구 및 서비스를 추가로 입력할 수 있겠죠. 이 때 고민거리가 생길 수 있습니다.
첫 번째는 환경이 변하는 경우입니다. 이직을 한 직후 사용하는 언어와 개발 환경이 바뀐 경우 개인정보에서 이를 수정해야 할 수 있습니다. 경력이 오래 되어 더 이상 사용하지 않게 된 기술들이 생긴 경우 그것들이 자신을 나타내는 정보라고 보기에도 석연치가 않습니다. 마찬가지로 수정이 필요합니다.
두 번째는 항목 간의 상대적 중요도 차이가 생기는 경우입니다. ‘사용할 줄은 아는데 이걸 굳이 쓰는 게 맞는 걸까? 그렇다고 빼자니 아쉽고…’ 와 같은 고민은 경험한 기술들이 많으면 많을수록 느끼기 쉽습니다. 이럴 때는 여러 가지 전문기술들 중에서 선택을 해야합니다. 기업 또한 이와 같은 일들이 생길 수 있습니다.
이와 같은 문제 때문에 전문기술 정보를 입력한다는 것은 다른 정보와 비교해 상대적으로 어려운 면이 있습니다. 하지만 위에서 말했듯이 전문기술 정보는 상당히 중요한 정보입니다. 이용자가 이를 잘 입력할 수 있도록 도와줄 수 있다면 입력하는 사람에게도 그 정보를 보는 사람에게도 많은 도움이 될 것입니다. 어떻게 하면 더 잘 입력하게 할 수 있을까요?
첫 번째 방법
많이 입력할 것 같은 전문기술들의 목록을 입력란 바로 아래에 나열해 놓고, 클릭하면 입력이 되도록 했습니다. 실제로 이용자들이 입력한 것들을 세어보면 어떤 것들이 있는지 금방 알 수 있습니다. Python, Linux, AWS, UI/UX 등등이 있겠죠. 하지만 이 방법은 명확한 한계가 있습니다. 자주 나오는 전문기술을 가진 이용자들은 쉽게 입력을 할 수 있겠지만 그렇지 않은 경우는 이 방법의 혜택을 받을 수 없습니다. 여러 가지를 입력해야 하는 경우 전부 목록에 있으면 좋겠지만 그렇지 않은 경우 자칫 입력을 빠뜨릴 수 있기도 합니다.
두 번째 방법
이용자가 입력한 전문기술들을 바탕으로 다음에 입력할 것을 추천해 줄 수 있다면 가장 좋을 것이라고 생각했습니다. 바로 아래와 같은 모습으로요.
- 첫 번째 예시

- 두 번째 예시
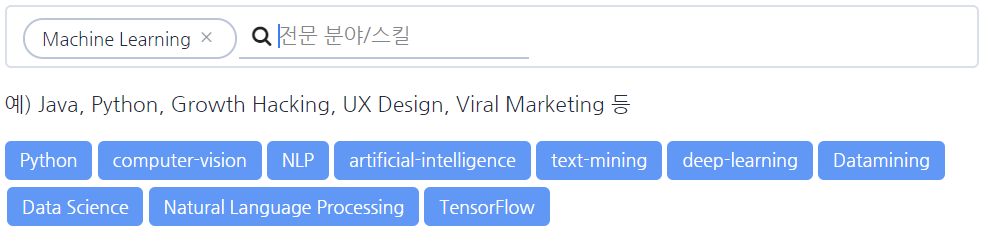
Collaborative Filtering
위와 같은 경우에 사용할 수 있는 추천 기법은 collaborative filtering이 있습니다. 간단히 말해 “X를 좋아하는 사람은 대개 Y를 좋아합니다. 당신은 X를 좋아하시죠, Y는 어떠십니까?” 라는 방식과 비슷합니다. 이용자가 있고 각각의 이용자들이 좋아하는 아이템들의 목록이 있을 때 제일 먼저 아이템 간의 유사도를 구합니다. 아이템 개수가 N일 때 N*N 행렬로 각 아이템 간의 유사도를 나타낼 수 있습니다. 임의의 아이템들이 주어졌을 때 이 행렬을 이용해 가장 유사한 아이템이 어떤 것인지 쉽게 계산할 수 있습니다. 아래와 같은 유사도 행렬이 있다고 해보겠습니다.
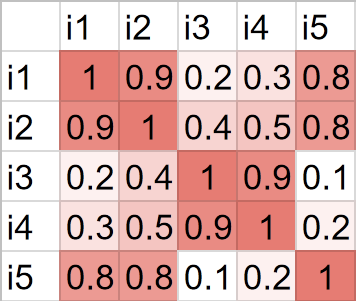
다섯 개의 아이템(i1, i2, …, i5)이 있을 때 각각의 유사도를 나타낸 행렬입니다. 유사도는 0과 1사이의 값을 가진다고 가정했습니다. i1과 i2는 0.9로 상당히 비슷하다고 할 수 있습니다. 반면 i3과 i5는 0.1로 낮은 유사도를 가지고 있습니다. 이 때 어떤 사람이 i1과 i2를 좋아한다고 가정해보겠습니다. 이 사람이 선택한 i1과 i2를 가지고 다른 아이템을 추천할 수 있습니다. i1의 유사도 row는 (1, 0.9, 0.2, 0.3, 0.8)입니다. i2는 (0.9, 1, 0.4, 0.5, 0.8)이죠. 단순히 이 둘을 더하면 (1.9, 1.9, 0.6, 0.8, 1.6)이 됩니다. i1과 i2는 이미 골랐으니 가장 높은 값을 가지는 아이템은 i5입니다. 간단하게 이런 방법으로 추천을 할 수 있습니다.
로켓펀치에서는 유사도 행렬을 계산하는 부분과, 그 행렬을 가지고 아이템을 추천하는 부분 크게 두 가지로 나누어 개발했습니다. 처음에는 이 두 가지가 모두 웹서버에 모듈로 붙어 있었습니다. 여러 가지 이슈 때문에 이를 분리해서 AWS Lambda로 옮기기로 했습니다. 비정기적으로 일어나는 task를 처리하기 위해 서버 자원을 항상 실행하고 있을 필요가 없다는 점 외에도 여러 가지 장점이 있습니다(또 다른 사례 및 자세한 내용은 이 글을 참고하시면 좋습니다). 잘만 분리한다면 꽤 괜찮은 선택이 될 것 같았고, 큰 문제없이 분리가 되었습니다. 그런데…
문제 발생
AWS Lambda는 한 번 실행이 되면 그 때부터는 초기 리소스 로딩 비용이 없이 계속 호출이 되는 특징이 있습니다. 그리고 주기적으로 초기 시작을 하는데, 이 초기 시작 때 행렬을 가져와서 메모리에 올리는데 시간이 너무 오래 걸리는 것이었습니다. 이용자가 입력했을 때 즉시 계산을 완료해 입력 칸 아래에 추천을 해야 하는데 이것이 수십초씩 걸리는 것은 안 될 말입니다. 메모리에 올리는 것 그 자체도 문제였죠. AWS Lambda는 사용한 메모리와 실행 시간에 비례해 요금을 내야하기 때문입니다.
해결 방법
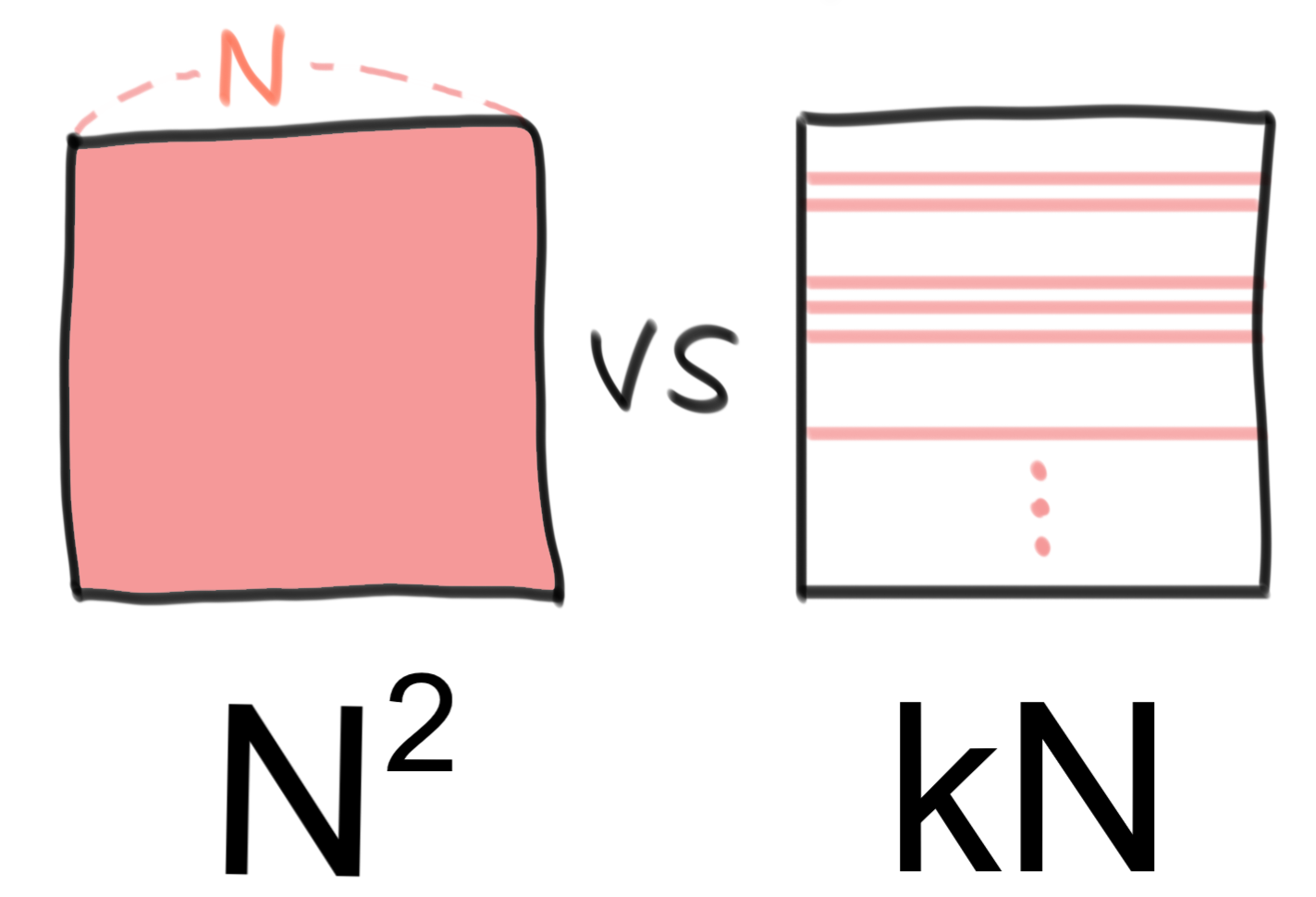
처음에 웹 서버에 실행하는 것을 생각해 유사도 정보를 메모리에 올린 것인데 접근 방법을 조금 다르게 할 필요가 있었습니다. 해결 방법은 생각보다 복잡하지 않았습니다. 사실 추천 과정에서 모든 전문기술의 유사도를 가지고 있을 필요는 없습니다. 바로 입력 칸에 있는 전문기술들과 다른 전문기술의 유사도 목록, 즉 커다란 행렬에서 row만 있으면 됩니다. 위 유사도 행렬 예시에서 알 수 있듯이, 유저가 고른 아이템이 i1, i2 뿐이라면 그 두 아이템의 유사도 row만 있으면 계산이 가능합니다. 이해를 돕기 위해 아래에 그림과 단순화한 코드를 첨부했습니다.
# 개선 전 similarity_matrix = get_similarity_matrix() # 커다란 매트릭스를 메모리에 올리는데 상당한 시간과 서버 자원을 사용 for _id in user_input: result += similarity_matrix[_id] # 개선 후 for _id in user_input: result += get_row_from_redis(_id) # 계산에 필요한 row만 가져와서 사용
이러면 N*N의 메모리를 사용하던 것을 k*N(k는 최대 수십 개 정도)의 공간만으로 해결할 수 있습니다. 각각의 row를 elasticache(redis)에 저장한 다음, 호출이 있을 때마다 필요한 row를 불러 간단하고 빠르게 계산을 마칠 수 있습니다. 입력한 전문기술 숫자만큼 redis 호출을 해야 하지만 실제 서비스가 되는 과정에서 평균 호출 시간이 100ms 미만임을 확인했습니다. 이 정도면 괜찮은 수준입니다.
마치며
간단한 알고리즘을 로컬에서 실행해 결과를 보는 것과 실제 서비스에 적용하는 것의 간극을 극복하고, 변하는 환경에서 일어나는 문제들을 해결하는 것이 바로 소프트웨어 엔지니어가 하는 일입니다. 로켓펀치는 멋진 이용자 경험을 제공하기 위해 데이터 분석을 통한 각종 기법들을 서비스에 적용할 예정입니다.
+ 로켓펀치를 함께 만들어 갈 인재들을 기다리고 있습니다.
– 글쓴이 : 로켓펀치 머신러닝 엔지니어 정희동