[ 왜 UX 개편을 할까요? ]
UX(User eXperience)란 고객이 서비스를 이용하는 과정에서 겪는 경험입니다. 사용자가 서비스를 사용하는 목적에 맞게 필요한 기능을 제공하고 목적을 달성할 수 있도록 서비스 구조를 면밀하게 설계합니다. UX에 개선 요소가 있거나, 기존의 서비스에서 확장된 더 큰 가치를 전달하려는 과정에서 UX 개편을 하게 됩니다.
[ 로켓펀치는 왜 UX 개편을 시작하였나? ]
<로켓펀치>는 스타트업을 위한 채용 서비스로 시작하여 기업, 채용 등 비즈니스 관련 10억 건의 데이터를 축적하며 연간 200만 명 이상이 편리하게 사용할 수 있는 온라인 네트워킹 서비스를 제공했습니다. 이 과정에서 ‘개인 프로필에 더 많은 내용을 입력할 수 있게 해주세요.’, ‘사람을 더 쉽게 찾을 수 있게 해주세요.’ 등 서비스 개선 목소리를 들었습니다. 이를 바탕으로 대한민국 전체 경제 인구에게 필요한 비즈니스 네트워킹 서비스를 제공하기 위해 2017년 말부터 UX 개편 프로젝트를 시작하였습니다.
[ ‘비즈니스 네트워킹 서비스’로 성장하기 위해 필요한 것 ]
개인 프로필과 네트워킹 기능을 강화한 <로켓펀치>를 간단하게 설명하자면 다음과 같습니다.
1. 더 다양한 이야기를 공유하고 상호작용 할 수 있습니다,
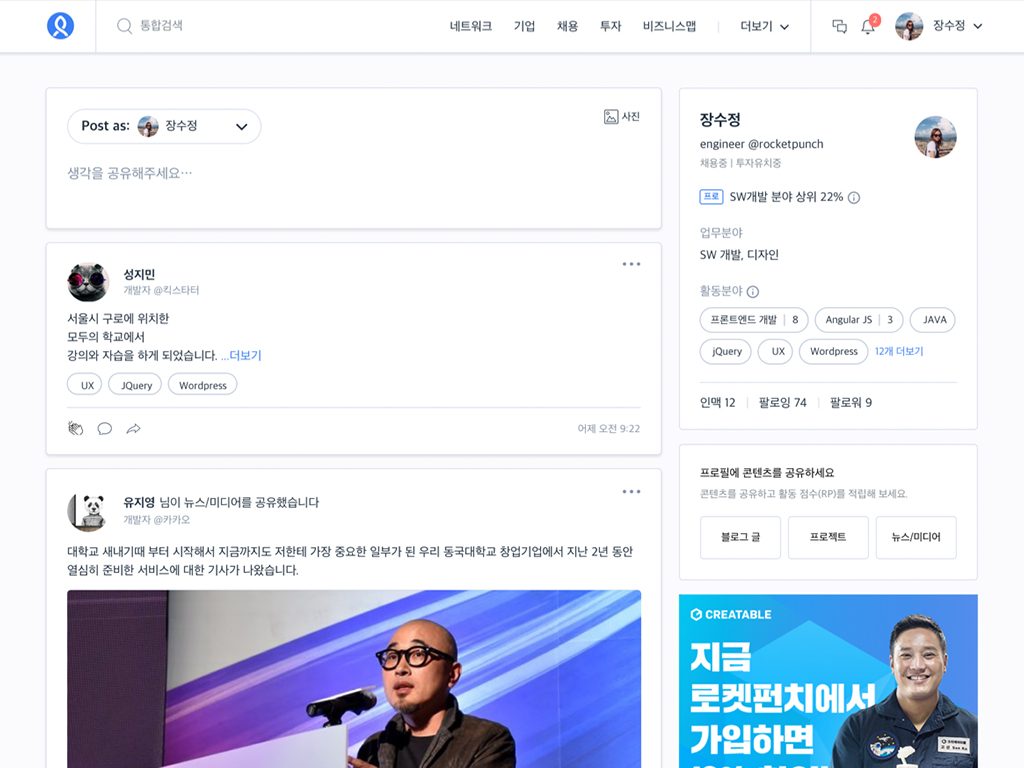
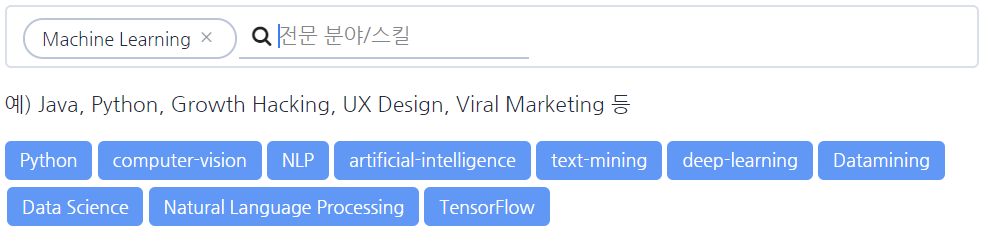
▲ 사용자의 정보를 더 쉽게 전달하게 된 <로켓펀치> 홈
경력 사항, 프로젝트 이력 등으로는 표현하기 힘든 이야기를 공유할 수 있도록 게시글을 작성하고 관심있을 정보를 쉽게 조회할 수 있게 홈을 개편하였습니다. 전문가 및 채용 정보, 기업 뉴스 등을 각각 정해진 영역에서 볼 수 있었던 개편 전 서비스 UI(User Interface)에 비해 사용자들이 필요한 정보를 더 쉽게 접하게 되었고 추천, 댓글, 공유 등 상호작용을 원활하게 할 수 있게 되었습니다.
2. 활동 분야 태그와 랭킹을 통해 프로를 더 쉽게 찾을 수 있습니다.
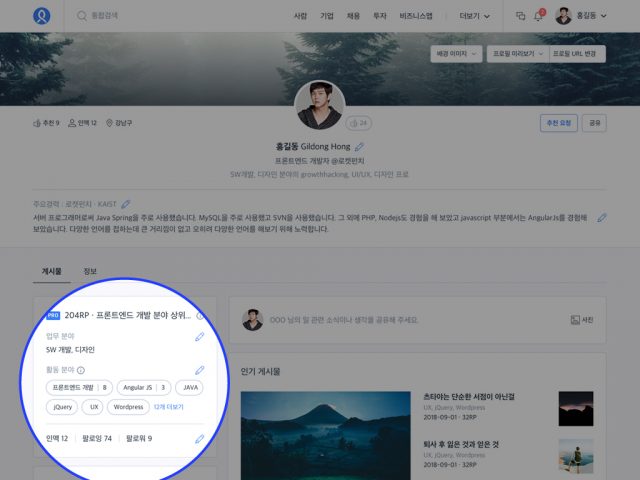
▲ 활동 분야를 나타내는 포인트와 ‘프로’ 뱃지
각 분야별 프로를 더 쉽게 찾을 수 있도록 태그 적용을 확대하고 랭킹 개념을 도입했습니다. 사용자의 활동에 따라 포인트가 쌓이고, 포인트가 높은 사용자는 각 분야별 프로 검색 시 상위에 노출됩니다. 분야별로 상위에 랭킹된 사용자는 ‘프로’ 뱃지도 받을 수 있습니다.
[ UX 개편, 그 시작과 진행 과정 ]
<로켓펀치>의 UX 개편 프로젝트는 2017년 말 시작되어 2018년 11월에 완료되었습니다.
약 1년이 소요된 프로젝트, 어떤 일들이 있었을까요?

▲ UX 개편 과정 중 진행했던 스프린트 모습
먼저 팀원 전체가 함께 모여 홈 개편을 포함한 전체 사이트의 방향성에 대해 의견을 나누었습니다. 큰 그림을 그리는 일부터, 세부적인 정책을 도출할 때까지 함께 회의했습니다.
타겟 고객 이해도를 높이기 위해 사용자 인터뷰도 진행했습니다. 현업 IT 종사자, 창업을 계획하는 예비 스타트업 대표, 창업을 하여 사업을 진행 중인 기업 대표까지 총 3명의 인터뷰를 바탕으로 인사이트를 추출하고, 핵심 컨셉을 설정했습니다.
핵심 UX를 정의하기 위해 5일간 스프린트 워크숍을 열기도 했습니다. 이후 집중해야 할 것들을 정리하고 세부 정책을 만들어가면서 마지막으로 브랜드 및 개편 방향을 재검토하며 UX 개편 준비를 마쳤습니다.
[ 함께 진행된 ‘리브랜딩’ 프로젝트 ]
새로운 UX를 위한 아이디어와 전략을 다듬은 뒤, 리브랜딩 프로젝트를 함께 진행했습니다. 채용 중심의 ‘스타트업 네트워킹 플랫폼’에서 확장하여 ‘비즈니스 네트워킹 서비스’을 명확하게 전달할 수 있는 브랜드 전략을 수립하기 위해 <로켓펀치>는 크리에이티브 솔루션 기업 <슬로워크>와 협업하였습니다.

[ 계획대로 서비스를 출시하기 위한 원칙 5가지 ]
<로켓펀치> UX 개편은 전체적으로 볼 때 약 1년이라는 시간이 걸린 대형(?) 프로젝트였지만, 실제로 디자인/개발 기간은 2개월 정도로 아주 짧았습니다. <로켓펀치>의 브랜드 방향성과 그에 따른 제품 및 서비스 방향에 대한 고민이 길어지면서 [리서치-아이디어-회의-디자인-전면 수정] 과정을 여러번 진행했습니다. 2018년 9월에 개편 방향성이 확정되었고 이 후 본격적으로 디자인과 개발이 시작되었습니다. 실제 개발은 전체 디자인이 나온 10월부터 약 한 달 정도 진행되었고 2018년 11월 1일, 새로운 <로켓펀치>를 세상에 선보였습니다.
오랜 고민과 많은 시행착오 끝에 완료된 <로켓펀치> UX 개편 프로젝트. 팀원들은 어떤 것을 깨달았을까요? <로켓펀치>에서는 UX 개편 완료 후, KPT* 방법을 활용해 팀원 전체가 프로젝트를 리뷰하는 시간을 가졌습니다.
(*KPT 방법론이란? Keep, Problem, Try 의 약자. 다음 프로젝트를 진행할 때도 유지할 것(Keep), 프로젝트를 진행하면서 문제가 되었던 것(Problem), 다음 프로젝트 진행 시 시도할 것(Try)으로 구분지어 회고하는 방법)
<리뷰에 참여한 사람들>
| 윤유진 PM @로켓펀치 |
정예연 제품디자이너 @로켓펀치 |
지광훈 제품디자이너 @로켓펀치 |
김동희 CTO @로켓펀치 |
김재찬 프로그래머 @로켓펀치 |
정경훈 프로그래머 @로켓펀치 |
이상범 CSO @로켓펀치 |
1. 서비스 출시 날짜 포함한 세부 일정을 지키려고 노력
이상범 CSO @로켓펀치
“Done Is Better Than Perfect”. 초기 계획했던 서비스 스펙을 조정하는 일이 있더라도 사업 계획에 맞춰 UX 개편을 마친 것이 좋았습니다.
김동희 CTO @로켓펀치
고정된 일정에 맞춰 서비스 스펙을 조정하고, 개발 리소스를 분배하며 진행하여 짧은 시간 내에 성공적으로 서비스를 출시할 수 있었습니다.
지광훈 제품디자이너 @로켓펀치
팀 단위로 일정별로 진행해야 하는 업무를 정의하고, 꼭 지키려고 노력한 덕에 좋은 성과가 있었습니다.
윤유진 PM @로켓펀치
일정을 기준으로 작업할 양을 조정해서 프로젝트 지연 없이 계획한 날짜에 릴리즈할 수 있었습니다.
2. 개발 및 디자인 작업 기간은 신중하게 잡기
윤유진 PM @로켓펀치
작업 기간은 프로젝트 진행 중 발생할 수 있는 다양한 변수를 고려하여 더 신중하게 계획해야 할 것 같습니다. 이번 프로젝트는 서비스 스펙에 비해 디자인 및 개발 작업 기간을 너무 짧게 잡았습니다. 그러다 보니 개발이 완료되기 전 QA를 해야 하는 상황이 발생하기도 했습니다.
김재찬 프로그래머 @로켓펀치
정책이나 디자인은 언제나 바뀔 수 있다고 생각하고, QA까지 고려하여 일정을 잡아야 합니다. 그리고 가능하다면 모듈별로 개발을 좀 더 일찍 시작할 수 있으면 좋겠습니다.
3. 할 수 있는 것부터 효율적 진행해서 시간 낭비 줄이기
김동희 CTO @로켓펀치
이번에는 기획과 디자인을 다 마친 뒤 개발을 시작했는데, 부분적으로 개발을 좀 더 일찍 시작할 수 있었을 것 같습니다. 디자인 쪽에서 전체 파트가 완성되길 기다리는 것보다 중요 파트를 요청하고 진행했으면 시간을 더 효율적으로 사용할 수 있었다고 생각합니다.
정경훈 프로그래머 @로켓펀치
결과론적인 얘기지만 기획과 디자인이 끝나기 전이라도 구현을 시작할 수 있었던 게 더 있지 않았을까 생각합니다.
4. 팀 간 커뮤니케이션을 더 일찍 시작하기
정예연 제품디자이너 @로켓펀치
디자인팀과 기획팀, 개발팀 사이 커뮤니케이션이 아쉬웠습니다. 특히 개발팀과의 커뮤니케이션은 디자인 완성 후 개발이 시작되면 활성화되었는데 좀 더 일찍 시작하면 이후 커뮤니케이션에 필요한 시간을 절약할 수 있었을 것 같습니다.
윤유진 PM @로켓펀치
개발 담당자들이 각 기능들을 더 일찍 리뷰하고 디자이너, CTO, PM 등 관계자와 의견을 공유하는 것이 필요합니다.
김동희 CTO @로켓펀치
초기에 기획팀, 디자인팀, 개발팀이 같이 주요 기능에 대해 같이 논의하여 예상되는 문제점들을 일찍 공유하면 더 효율적으로 프로젝트를 진행할 수 있을것 같습니다.
5. 효율적인 업무 진행에 필요한 도구 적극적으로 활용하기
정예연 제품디자이너 @로켓펀치
기존에 원격으로 업무를 진행하면서 불편하다고 느꼈던 디자인 논의와 디자인 자료 공유가 ‘인비전 프리핸드’ 활용으로 많이 개선되었습니다.
김재찬 프로그래머 @로켓펀치
계속 업데이트 되는 정책서 변경 사항을 파악하기가 어려웠습니다. 수정된 사항들을 쉽게 파악할 수 있게 새로운 도구를 써보는 것이 어떨까 합니다. (Git + Markdown 등)
큰 프로젝트를 진행하다보니 각 기능별 디자인 파일을 찾기가 어려웠습니다. 파일 관리 규칙을 정하거나 적절한 도구를 활용하여 개선할 수 있을것 같습니다.
정경훈 프로그래머 @로켓펀치
현재 스펙 문서 도구로 Google Docs를 쓰고 있는데, 특정 날짜 기준으로 전후 수정 사항을 쉽게 보기 힘들었습니다. 적절한 도구를 활용하면 효율적으로 개발 진행을 할 수 있을것 같습니다.
[ 로켓펀치의 약속 ]
<로켓펀치>는 경제 인구가 일하면서 겪는 어려움을 해결하기 위해 끊임없이 진화하고 있습니다. 2013년, 스타트업의 채용 문제를 해결하기 위해 서비스를 시작하여 이제는 대한민국 경제 인구를 위한 비즈니스 네트워킹 서비스를 목표로 합니다. 신뢰할 수 있는 경험 정보를 나누고, 폭넓은 비즈니스 교류가 활성화되는 것, 이때 핵심은 바로 사람과 사람 간 연결입니다. 이 연결을 보다 편하고 자연스럽게 이어나갈 수 있도록 <로켓펀치>는 고객의 목소리에 귀기울이고 더 좋은 서비스를 제공하도록 꾸준히 노력하겠습니다.